

Constat d’une erreur sur l’écran du serveur ou via un mail du système :
Exemple de message d’erreur :
This is an automatically generated mail message from mdadm running on brawndo
A DegradedArray event had been detected on md device /dev/md1.
> /proc/mdstat file currently contains the following:
Personalities : [raid1]
md1 : active raid1 sdc2[1]
249869120 blocks super 1.2 [2/1] [_U]
md0 : active raid1 sda1[2] sdc1[1]
498368 blocks super 1.2 [2/2] [UU]
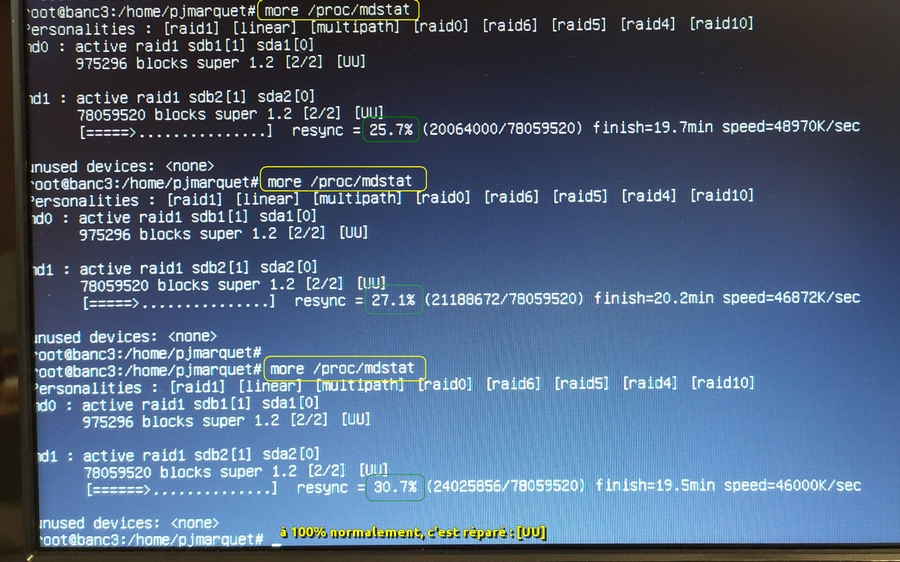
Surveiller la fin de la réparation automatique (resync) dans le fichier /proc/mdstat
La réparation automatique peut prendre plusieurs minutes jusqu’à 1 heure…
Tant que la resync n’est pas à 100% [UU] erreur résolue par le RAID ? : # more /proc/mdstat
NB : Voir aussi l’article du magazine Linux acheté à Bordeaux début décembre 2017 !!!
On peut archiver l’erreur de RAID miroring en exécutant la commande :
# cat /proc/mdstat > [date]-proc-mdstat.error
Si on a toujours : [ _U] (erreur de RAID) … ça devrait être [UU] si tout est “UP”…
>> Le md1 a perdu un disque : sda est plus ou moins HS.
Dans le doute, on peut remplacer le disque défectueux.
Vérifications supplémentaires :
# mdadm –detail /dev/md0
# mdadm –detail /dev/md1
Afficher un extrait de dmesg (display message) , commande très utile en cas de problème ou juste pour avoir des informations sur le matériel / drivers sur un système :
# dmesg | grep 'md' [ 1.651041] Refined TSC clocksource calibration: 3095.989 MHz. [ 1.651047] Switching to clocksource tsc [ 1.839664] md: md0 stopped. [ 1.840363] md: bind<sdc1> [ 1.840575] md: bind<sda1> [ 1.841346] md: raid1 personality registered for level 1 [ 1.841452] bio: create slab <bio-1> at 1 [ 1.841487] md/raid1:md0: active with 2 out of 2 mirrors [ 1.841502] md0: detected capacity change from 0 to 510328832 [ 1.842657] md0: unknown partition table [ 2.044854] md: md1 stopped. [ 2.045505] md: bind<sda2> [ 2.045674] md: bind<sdc2> [ 2.045686] md: kicking non-fresh sda2 from array! [ 2.045688] md: unbind<sda2> [ 2.066090] md: export_rdev(sda2) [ 2.067072] md/raid1:md1: active with 1 out of 2 mirrors [ 2.067084] md1: detected capacity change from 0 to 255865978880 [ 2.088070] md1: unknown partition table
Pour remplacer le disque défaillant, on doit connaître la taille minimum du nouveau disque :
# fdisk -l /dev/sda (Si un disque est HS, executer fdisk sur l'autre)
Avant de sortir le disque défectueux /dev/sda du RAID, il faut :
2) le marquer “fault” dans md1 ET dans md0
# mdadm --manage /dev/md1 --fail /dev/sda2 # mdadm --manage /dev/md0 --fail /dev/sda1
Donc, voici maintenant l’état actuel du raid :
# cat /proc/mdstat Personalities : [raid1] md1 : active raid1 sdc2[1] 249869120 blocks super 1.2 [2/1] [_U] md0 : active raid1 sda1[2](F) sdc1[1] 498368 blocks super 1.2 [2/1] [_U]
2) Il faut maintenant “enlever” le device en fault du RAID (md0 ET md1):
# mdadm --manage /dev/md1 --remove /dev/sda2
mdadm: hot removed /dev/sda2 from /dev/md1
# mdadm --manage /dev/md0 --remove /dev/sda1
mdadm: hot removed /dev/sda1 from /dev/md0
root@brawndo:~# cat /proc/mdstat Personalities : [raid1] md1 : active raid1 sdc2[1] 249869120 blocks super 1.2 [2/1] [_U] md0 : active raid1 sdc1[1] 498368 blocks super 1.2 [2/1] [_U]
Pour la suite, il faut installer un disque dur SATA neuf qui rentre dans la boîte (!).
Voici les caractéristiques de sdc pour refaire pareil sur un neuf :
# fdisk -l /dev/sdc Disque /dev/sdc : 320.1 Go, 320072933376 octets 255 têtes, 63 secteurs/piste, 38913 cylindres, total 625142448 secteurs Unités = secteurs de 1 * 512 = 512 octets Taille de secteur (logique / physique) : 512 octets / 512 octets taille d'E/S (minimale / optimale) : 512 octets / 512 octets Identifiant de disque : 0x09feadbb Périphérique Amorce Début Fin Blocs Id Système /dev/sdc1 * 2048 999423 498688 fd RAID Linux autodétecté /dev/sdc2 999424 501000191 250000384 fd RAID Linux autodétecté
L’important est de refaire les même partitions avec les mêmes début/fin (au moins pour md0)
D’ailleurs si tu regardes le disque sda :
root@brawndo:~# fdisk -l /dev/sda Disque /dev/sda : 500.1 Go, 500107862016 octets 255 têtes, 63 secteurs/piste, 60801 cylindres, total 976773168 secteurs Unités = secteurs de 1 * 512 = 512 octets Taille de secteur (logique / physique) : 512 octets / 4096 octets taille d'E/S (minimale / optimale) : 4096 octets / 4096 octets Identifiant de disque : 0xdc8415f9 Périphérique Amorce Début Fin Blocs Id Système /dev/sda1 * 2048 999423 498688 83 Linux /dev/sda2 999424 501000191 250000384 fd RAID Linux autodétecté
On voit encore les bonnes partitions, si ce n’est le type de la sda1.
Ensuite on peut faire # smartctl -a /dev/sda pour diagnostiquer le disque, voici un extrait :
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 104 099 006 Pre-fail Always - 7023648
3 Spin_Up_Time 0x0003 100 100 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 32
5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 079 060 030 Pre-fail Always - 83887505
9 Power_On_Hours 0x0032 051 051 000 Old_age Always - 43127
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 31
183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0
184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0
189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0022 066 047 045 Old_age Always - 34 (Min/Max 27/39)
194 Temperature_Celsius 0x0022 034 053 000 Old_age Always - 34 (0 16 0 0)
195 Hardware_ECC_Recovered 0x001a 017 017 000 Old_age Always - 7023648
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 43963285284982
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 1358926627
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 1235851680
En l’occurrence, il a 43127 heures de fonctionnement (power on), soit l’équivalent de 5 ans (diviser par 24h x 365j). C’est déjà pas mal !
On pourrait s’amuser à lancer un self-test pour voir mais je préfère ne pas trop jouer avec une machine qui tourne sur un seul disque ! Bref, entre les Pre-fail et les Old_age, il semble qu’on a bien à faire à un bon vieux disque dur…
D’ailleurs, c’est pareil pour l’autre, mais pas grave. On le remplacera quand il nous lâchera.
Prochaine étape, installer un beau disque tout neuf d’env. 500 Go à partitionner avec fdisk ou mieux sfdisk, afin de faire la même table de partoches.
Rallumer le serveur avec le nouveau disque dur à la place de l’autre (non partitionné et non formatté : pas la peine) :
1) Lister les partitions pour ne pas se tromper de disque ! # fdisk -l
Disque /dev/sda : 55,9 GiB, 60022480896 octets, 117231408 secteurs
Identifiant de disque : 0x1231d40d
Disque /dev/sdb : 931,5 GiB, 1000204886016 octets, 1953525168 secteurs
Identifiant de disque : 0x4f61b4f9
Disque /dev/sdc : 465,8 GiB, 500107862016 octets, 976773168 secteurs
… Identifiant de disque : 0xdc8415f9
2) Cloner les (bonnes) partitions :
# sfdisk -d /dev/sdc | sfdisk /dev/sdb
3) Lister les partitions pour vérifier que le clônage est OK : $ fdisk -l
——— UUID ? : # blkid
Puis il faudra faire dessus (en admettant que c’est /dev/sdx) :
# mdadm --zero-superblock /dev/sdx (pas fait KO mais ça passe qd meme)
Ensuite re-vérifie fdisk quand même… Tu dois avoir exactement :
Périphérique Amorce Début Fin Blocs Id Système /dev/sdx1 * 2048 999423 498688 fd RAID Linux autodétecté /dev/sdx2 999424 501000191 250000384 fd RAID Linux autodétecté
(sdx1 est bien bootable car elle sert de boot…)
Noter aussi son UUID et sa taille exacte pour être sûr de le trouver de façon fiable quand tu le mettras dans brawndo.
On peut aussi Agrandir le volume md1 du RAID : http://linux.1ere-page.fr/etendre-partition-lvm-a-taille-maximum-disque/
Ensuite, un jeu d’enfant, tu vas faire un truc du genre :
# mdadm --manage /dev/md0 --add /dev/sdx1
Tu attends la fin de la restauration des données sur le nouveau disque :
# watch cat /proc/mdstat
(CTR + C pour sortir) Ca doit aller vite sur celle-ci, c’est juste une petiote de boot. Puis tu fais pareil sur l’autre partoche :
# mdadm --manage /dev/md1 --add /dev/sdx2
# watch cat /proc/mdstat
C’est plus long, d’où l’intérêt du watch toutes les 2s.
C’est pas tout à fait fini, pour couronner le tout, on installe grub sur le nouveau disque, sinon ça sert à rien de se prendre la tête à faire du raid à part pour le boot :
# grub-install /dev/sdx
C’est tout… Merci les nouvelles versions de grub !
Pour vérifier ce tuto, regarde https://www.howtoforge.com/replacing_hard_disks_in_a_raid1_array
Et normalement, maintenant t’as un nouveau RAID mirroring fonctionnel et rien à faire sur l’OS, les données, les packets, les users,… C’est merveilleux non ?
Email reçu d’Anatole le 31/10/2017 : Merci à lui !!!